INCREASING ENERGY EFFICIENCY ON THE SOFTWARE LAYER
April 13, 2017, 9:07 a.m.
OFFIS, by Christian Pieper and Daniel Schlitt
M2DC (Modular Microserver DataCentre) is an EU funded project, developing a new kind of server in order to significantly increase a system’s overall energy efficiency as well as TCO. The new hardware platform called RECS®|Box (version 4.0) continues work of previous EU projects (e.g. FiPS), resulting in a heterogeneous platform of different highly energy-efficient microservers. This comprises high performance and low power systems, as well as hardware accelerators like GPGPUs or FPGAs.
Increasing the energy efficiency requires actions on different layers. On the one hand we offer state of the art hardware based on different architectures, each of them efficient for designated tasks. This heterogeneous hardware platform enables different options regarding the deployment of workload. Therefore, there is the software layer on the other hand, which includes a sophisticated workload management. Its task is to place workload on the most efficient hardware platforms w.r.t. to given constraints, e.g. depending on priority or deadline.
A key aspect of OFFIS’ research affects the implementation of a Workload Management and its forecast component for heterogeneous hardware, considering the main question when to deploy different types of workload/applications on which platform. It basically evaluates the workload history of given applications, current task queues, and the present hardware utilisation. Using task queue information and hardware utilisation data enables to deploy workload on the most appropriate hardware for that moment. Urgent tasks could for instance be deployed on high performance microservers whereas low priority tasks could be processed on more efficient low power ARM based microservers. Workload of servers with low utilisation will be consolidated, while idling servers will be shut down. The forecast component, based on workload history, supports the proactive control of servers and thus allows controlling server states (starting or stopping servers) and deploying applications prior to expected increases of workload, avoiding long response times.
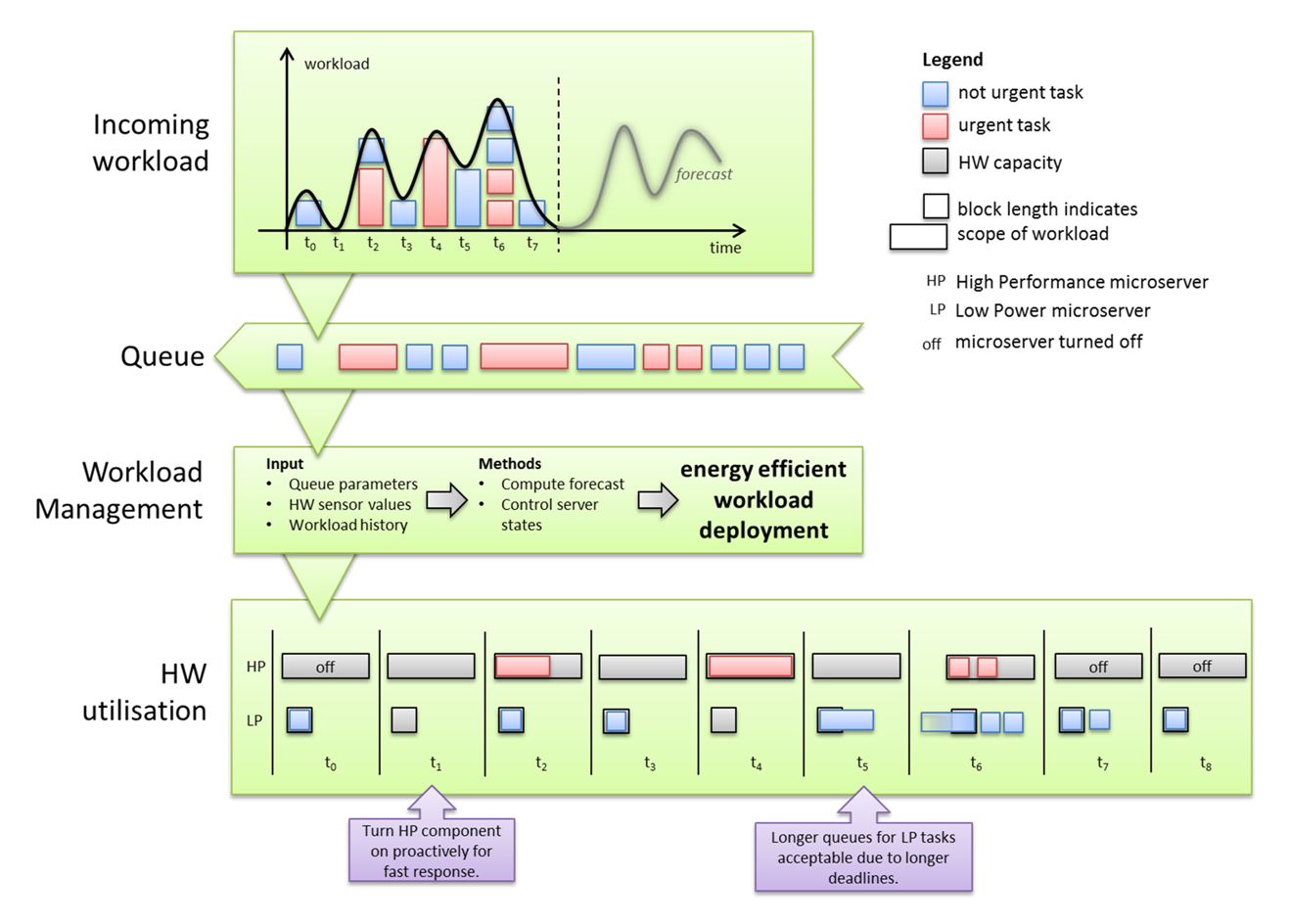
Figure 1: Deploy incoming workload on heterogeneous hardware
Figure 1 depicts a short scenario as example period. At first, there is an incoming workload which needs to be processed. It is abstracted to discrete blocks of different lengths, which indicate the scope of each incoming task, where red means an urgent task and blue a rather low priority one. They are placed in a queue, according to their appearance, and then assigned to hardware by the intelligent Workload Management in the bottom. There are two processing units, one high performance, and one low power microserver. Grey blocks indicate the possible workload capacity while the additional text “off” means the server has been turned off. In this example, the Workload Management always places not urgent tasks on low performance microservers, as happened in t0. In t1 there is no workload to process, but HP is already turned on to be prepared for the usual workload expected soon, while the LP remains online as a buffer for unexpected tasks. Although HP does not process tasks in t3 it has not been turned off, because the forecast expected some workload for the next steps. For t5 and t6, there is a situation where different not urgent tasks wait to be processed. As they have a rather long deadline, they are queued up for the more energy efficient LP to turn of the HP in the next steps instead.
In order to maximize the energy efficiency potential, the Workload Management tries to power down (or up) compute nodes aggressively. The target is to align the active compute resources to the actual demand to avoid wasting energy by being active idle. However, fluctuations in resource demand require the buffering of resources, as powered down compute nodes need some time until the resources are available again. Therefore, the Workload Management uses means for workload modelling and forecasting to reduce the amount of buffered resources needed.
Figure 2 depicts an example for typical workload behaviour at one of M2DC’s industrial partners, namely CEWE. Daily and weekly profiles are clearly visible with peaks in the evening and at weekend days, respectively. Moreover, there was a trend (red line) of rising mean as well as peak usage just before Christmas, which then afterwards just normalized to the regular workload profile.
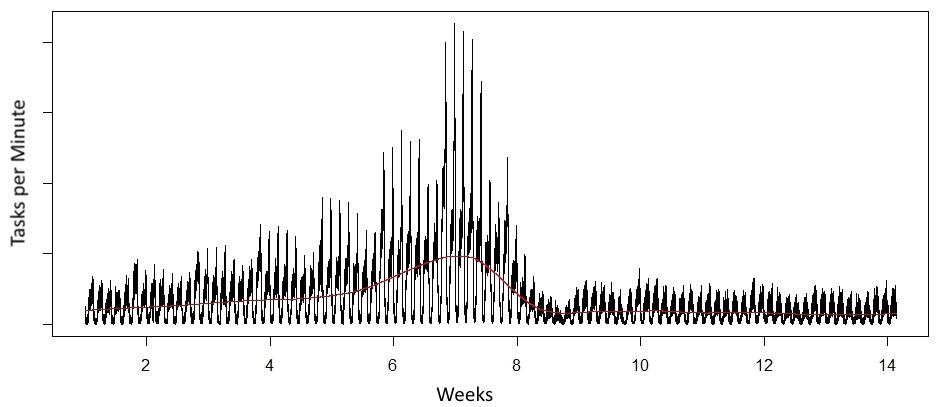
Figure 2: Example workload
By using statistical time series analysis, workload time series with time-variant behaviour such as the one in Figure 2 can be modelled and trained on the available historical data. The resulting trained models can then be used to estimate the future workload behaviour. There are several different methods such as seasonal and trend decomposition using Loess (STL), exponential modelling e.g. via Holt-Winters filtering, seasonal autoregressive integrated moving average (SARIMA) or the relatively new model Prophet, presented by Facebook. A suitable forecast for the example workload could be look like the blue trace in Figure 3.
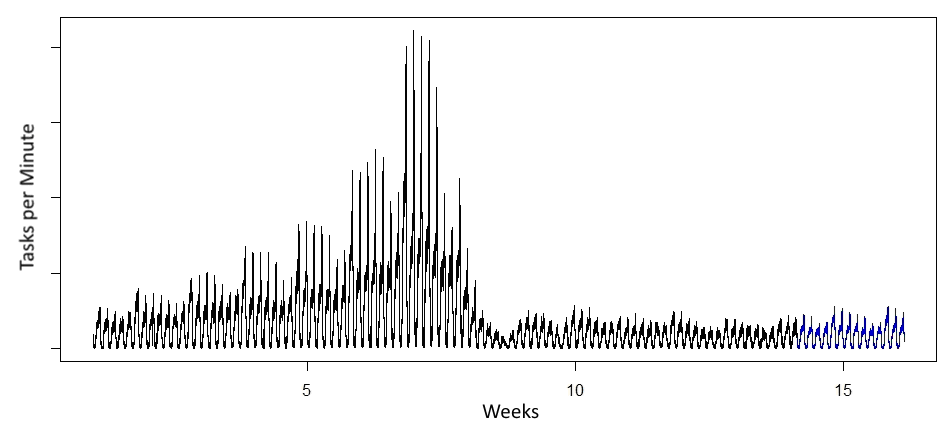
Figure 3: Forecast (blue trace) for example workload in Figure 2
Every method has its own (dis-)advantages and therefore may be better suited for certain workload behaviour than others. As the M2DC Workload Management shall work with general applications, the workload modelling will not be limited to a single approach, but it is planned to implement a decision algorithm, which applies different models on the available data and selects in each case the most appropriate model based on the forecast accuracy. Furthermore, the accuracy of workload models will be monitored over time as application or user behaviour may change and models will be adapted or changed based on this newly gained information.
The RECS®|Box’ middleware is based on an OpenStack environment, using the Nova component as scheduler. As the M2DC hardware platform differs from common platforms, Nova will be customized to support heterogeneous hardware and collaborate with the Workload Management, described above.